Multiple testing
Procedures
In the previous section we learned how p-values are no longer a useful quantity to interpret when dealing with high-dimensional data. This is because we are testing many features at the same time. We refer to this as the multiple comparison or multiple testing or multiplicity problem. The definition of a p-value does not provide a useful quantification here. Again, because when we test many hypotheses simultaneously, a list based simply on a small p-value cut-off of, say 0.01, can result in many false positives with high probability. Here we define terms that are more appropriate in the context of high-throughput data.
The most widely used approach to the multiplicity problem is to define a procedure and then estimate or control an informative error rate for this procedure. What we mean by control here is that we adapt the procedure to guarantee a error rate below a predefined value. The procedures are typically flexible through parameters or cutoffs that let us control specificity and sensitivity. An example of a procedure is:
- Compute a p-value for each gene.
- Call significant all genes with p-values smaller than .
Note that changing the permits us to adjust specificity and sensitivity.
Next we define the error rates that we will try to estimate and control.
Error Rates
Throughout this section we will be using the type I error and type II error terminology. We will also refer to them as false positives and false negatives respectively. We also use the more general terms specificity, which relates to type I error, and sensitivity, which relates to type II errors.
In the context of high-throughput data we can make several type I errors and several type II errors in one experiment, as opposed to one or the other as seen in Chapter 1. In this table, we summarize the possibilities using the notation from the seminal paper by Benjamini-Hochberg:
| Called significant | Not called significant | Total | |
|---|---|---|---|
| Null True | |||
| Alternative True | |||
| True |
To describe the entries in the table, let’s use as an example a dataset representing measurements from 10,000 genes, which means that the total number of tests that we are conducting is: . The number of genes for which the null hypothesis is true, which in most cases represent the “non-interesting” genes, is , while the number of genes for which the null hypothesis is false is . For this we can also say that the alternative hypothesis is true. In general, we are interested in detecting as many as the cases for which the alternative hypothesis is true (true positives), without incorrectly detecting cases for which the null hypothesis is true (false positives). For most high-throughput experiments, we assume that is much greater than . For example, we test 10,000 expecting 100 genes or less to be interesting. This would imply that and .
Throughout this chapter we refer to features as the units being tested. In genomics, examples of features are genes, transcripts, binding sites, CpG sites, and SNPs. In the table, represents the total number of features that we call significant after applying our procedure, while is the total number of genes we don’t call significant. The rest of the table contains important quantities that are unknown in practice.
- represents the number of type I errors or false positives. Specifically, is the number of features for which the null hypothesis is true, that we call significant.
- represents the number of true positives. Specifically, is the number of features for which the alternative is true, that we call significant.
This implies that there are type II errors or false negatives and true negatives.
Keep in mind that if we only ran one test, a p-value is simply the probability that when . Power is the probability of when . In this very simple case, we wouldn’t bother making the table above, but now we show how defining the terms in the table helps in practice the high-dimensional context.
Data example
Let’s compute these quantities with a data example. We will use a Monte Carlo simulation using our mice data to imitate a situation in which we perform tests for 10,000 different fad diets, none of them having an effect on weight. This implies that the null hypothesis is true for diets and thus and . Let’s run the tests with a sample size of and compute . Our procedure will declare any diet achieving a p-value smaller than as significant.
set.seed(1)
population = unlist( read.csv("femaleControlsPopulation.csv") )
alpha <- 0.05
N <- 12
m <- 10000
pvals <- replicate(m,{
control = sample(population,N)
treatment = sample(population,N)
t.test(treatment,control)$p.value
})
Although in practice we do not know the fact that no diet works, in this simulation we do, and therefore we can actually compute and . Because all null hypotheses are true, we know, in this specific simulation, that . Of course, in practice we can compute but not .
sum(pvals < 0.05) ##This is R
## [1] 462
These many false positives are not acceptable in most contexts.
Here is more complicated code showing results where 10% of the diets are effective with an average effect size of ounces. Studying this code carefully will help understand the meaning of the table above. First let’s define the truth:
alpha <- 0.05
N <- 12
m <- 10000
p0 <- 0.90 ##10% of diets work, 90% don't
m0 <- m*p0
m1 <- m-m0
nullHypothesis <- c( rep(TRUE,m0), rep(FALSE,m1))
delta <- 3
Now we are ready to simulate 10,000 tests, perform a t-test on each, and record if we rejected the null hypothesis or not:
set.seed(1)
calls <- sapply(1:m, function(i){
control <- sample(population,N)
treatment <- sample(population,N)
if(!nullHypothesis[i]) treatment <- treatment + delta
ifelse( t.test(treatment,control)$p.value < alpha,
"Called Significant",
"Not Called Significant")
})
Because in this simulation we know the truth (saved in nullHypothesis), we can compute the entries of the table:
null_hypothesis <- factor( nullHypothesis, levels=c("TRUE","FALSE"))
table(null_hypothesis,calls)
## calls
## null_hypothesis Called Significant Not Called Significant
## TRUE 421 8579
## FALSE 520 480
The first column of the table above shows us and . Note that and are random variables. If we run the simulation repeatedly, these values change. Here is a quick example:
B <- 10 ##number of simulations
VandS <- replicate(B,{
calls <- sapply(1:m, function(i){
control <- sample(population,N)
treatment <- sample(population,N)
if(!nullHypothesis[i]) treatment <- treatment + delta
t.test(treatment,control)$p.val < alpha
})
cat("V =",sum(nullHypothesis & calls), "S =",sum(!nullHypothesis & calls),"\n")
c(sum(nullHypothesis & calls),sum(!nullHypothesis & calls))
})
## V = 410 S = 564
## V = 400 S = 552
## V = 366 S = 546
## V = 382 S = 553
## V = 372 S = 505
## V = 382 S = 530
## V = 381 S = 539
## V = 396 S = 554
## V = 380 S = 550
## V = 405 S = 569
This motivates the definition of error rates. We can, for example, estimate probability that is larger than 0. This is interpreted as the probability of making at least one type I error among the 10,000 tests. In the simulation above, was much larger than 1 in every single simulation, so we suspect this probability is very practically 1. When , this probability is equivalent to the p-value. When we have a multiple tests situation, we call it the Family Wide Error Rate (FWER) and it relates to a technique that is widely used: The Bonferroni Correction.
The Bonferroni Correction
Now that we have learned about the Family Wide Error Rate (FWER), we describe what we can actually do to control it. In practice, we want to choose a procedure that guarantees the FWER is smaller than a predetermined value such as 0.05. We can keep it general and instead of 0.05, use in our derivations.
Since we are now describing what we do in practice, we no longer have the advantage of knowing the truth. Instead, we pose a procedure and try to estimate the FWER. Let’s consider the naive procedure: “reject all the hypotheses with p-value <0.01”. For illustrative purposes we will assume all the tests are independent (in the case of testing diets this is a safe assumption; in the case of genes it is not so safe since some groups of genes act together). Let be the the p-values we get from each test. These are independent random variables so:
Or if you want to use simulations:
B<-10000
minpval <- replicate(B, min(runif(10000,0,1))<0.01)
mean(minpval>=1)
## [1] 1
So our FWER is 1! This is not what we were hoping for. If we wanted it to be lower than , we failed miserably.
So what do we do to make the probability of a mistake lower than ? Using the derivation above we can change the procedure by selecting a more stringent cutoff, previously 0.01, to lower our probability of at least one mistake to be 5%. Namely, by noting that:
and solving for , we get
This now gives a specific example of a procedure. This one is actually called Sidak’s procedure. Specifically, we define a set of instructions, such as “reject all the null hypothesis for which p-values < 0.000005”. Then, knowing the p-values are random variables, we use statistical theory to compute how many mistakes, on average, we are expected to make if we follow this procedure. More precisely, we compute bounds on these rates; that is, we show that they are smaller than some predetermined value. There is a preference in the life sciences to err on the side of being conservative.
A problem with Sidak’s procedure is that it assumes the tests are independent. It therefore only controls FWER when this assumption holds. The Bonferroni correction is more general in that it controls FWER even if the tests are not independent. As with Sidak’s procedure we start by noting that:
or using the notation from the table above:
The Bonferroni procedure sets since we can show that:
Controlling the FWER at 0.05 is a very conservative approach. Using the p-values computed in the previous section…
set.seed(1)
pvals <- sapply(1:m, function(i){
control <- sample(population,N)
treatment <- sample(population,N)
if(!nullHypothesis[i]) treatment <- treatment + delta
t.test(treatment,control)$p.value
})
…we note that only:
sum(pvals < 0.05/10000)
## [1] 2
are called significant after applying the Bonferroni procedure, despite having 1000 diets that work.
False Discovery Rate
There are many situations for which requiring an FWER of 0.05 does not make sense as it is much too strict. For example, consider the very common exercise of running a preliminary small study to determine a handful of candidate genes. This is referred to as a discovery driven project or experiment. We may be in search of an unknown causative gene and more than willing to perform follow up studies with many more samples on just the candidates. If we develop a procedure that produces, for example, a list of 10 genes of which 1 or 2 pan out as important, the experiment is a resounding success. With a small sample size, the only way to achieve a FWER 0.05 is with an empty list of genes. We already saw in the previous section that despite 1,000 diets being effective, we ended up with a list with just 2. Change the sample size to 6 and you very likely get 0:
set.seed(1)
pvals <- sapply(1:m, function(i){
control <- sample(population,6)
treatment <- sample(population,6)
if(!nullHypothesis[i]) treatment <- treatment + delta
t.test(treatment,control)$p.value
})
sum(pvals < 0.05/10000)
## [1] 0
By requiring a FWER 0.05, we are practically assuring 0 power (sensitivity). In many applications, this specificity requirement is over-kill. A widely used alternative to the FWER is the false discover rate (FDR). The idea behind FDR is to focus on the random variable with when and . Note that (nothing called significant) implies (no false positives). So is a random variable that can take values between 0 and 1 and we can define a rate by considering the average of . To better understand this concept here, we compute for the procedure: call everything p-value < 0.05 significant.
Vectorizing code
Before running the simulation, we are going to vectortize the code. This means that instead of using sapply to run m tests, we will create a matrix with all data in one call to sample. This code runs several times faster than the code above, which is necessary here due to the fact that we will be generating several simulations. Understanding this chunk of code and how it is equivalent to the code above using sapply will take a you long way in helping you code efficiently in R.
library(genefilter) ##rowttests is here
set.seed(1)
##Define groups to be used with rowttests
g <- factor( c(rep(0,N),rep(1,N)) )
B <- 1000 ##number of simulations
Qs <- replicate(B,{
##matrix with control data (rows are tests, columns are mice)
controls <- matrix(sample(population, N*m, replace=TRUE),nrow=m)
##matrix with control data (rows are tests, columns are mice)
treatments <- matrix(sample(population, N*m, replace=TRUE),nrow=m)
##add effect to 10% of them
treatments[which(!nullHypothesis),]<-treatments[which(!nullHypothesis),]+delta
##combine to form one matrix
dat <- cbind(controls,treatments)
calls <- rowttests(dat,g)$p.value < alpha
R=sum(calls)
Q=ifelse(R>0,sum(nullHypothesis & calls)/R,0)
return(Q)
})
Controlling FDR
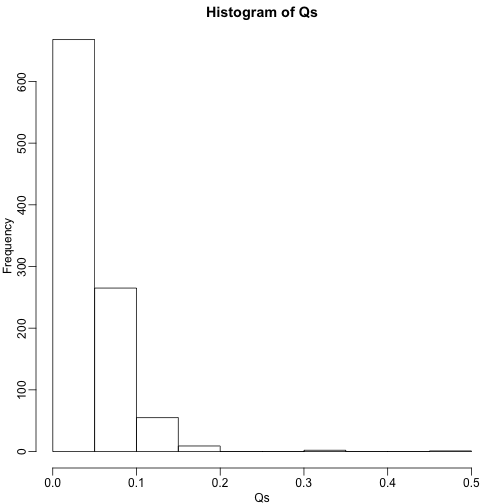
The code above is a Monte Carlo simulation that generates 10,000 experiments 1,000 times, each time saving the observed . Here is a histogram of these values:
library(rafalib)
mypar(1,1)
hist(Qs) ##Q is a random variable, this is its distribution
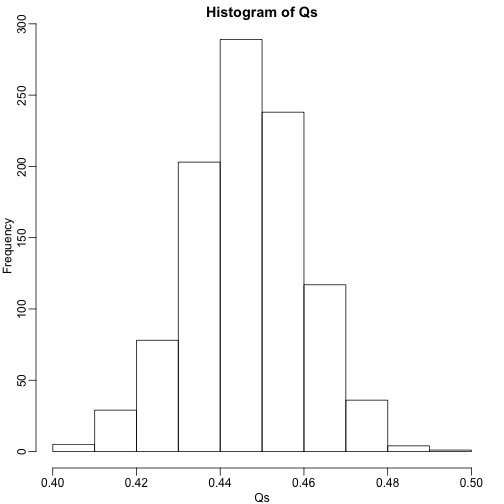
The FDR is the average value of
FDR=mean(Qs)
print(FDR)
## [1] 0.4463354
The FDR is relatively high here. This is because for 90% of the tests, the null hypotheses is true. This implies that with a 0.05 p-value cut-off, out of the 100 tests we incorrectly call between 4 and 5 significant on average. This combined with the fact that we don’t “catch” all the cases where the alternative is true, gives us a relatively high FDR. So how can we control this? What if we want lower FDR, say 5%?
To visually see why the FDR is high, we can make a histogram of the p-values. We use a higher value of m to have more data from the histogram. We draw a horizontal line representing the uniform distribution one gets for the m0 cases for which the null is true.
set.seed(1)
controls <- matrix(sample(population, N*m, replace=TRUE),nrow=m)
treatments <- matrix(sample(population, N*m, replace=TRUE),nrow=m)
treatments[which(!nullHypothesis),]<-treatments[which(!nullHypothesis),]+delta
dat <- cbind(controls,treatments)
pvals <- rowttests(dat,g)$p.value
h <- hist(pvals,breaks=seq(0,1,0.05))
polygon(c(0,0.05,0.05,0),c(0,0,h$counts[1],h$counts[1]),col="grey")
abline(h=m0/20)
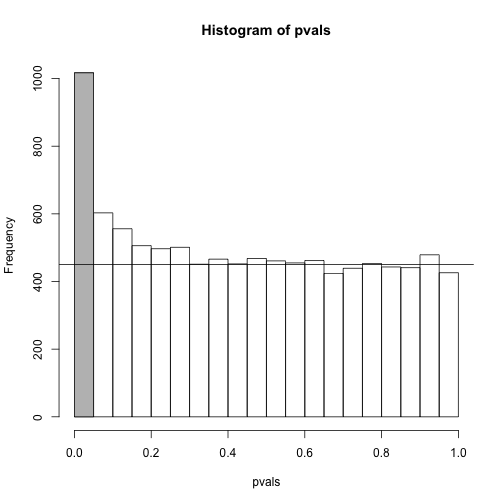
The first bar (grey) on the left represents cases with p-values smaller than 0.05. From the horizontal line we can infer that about 1/2 are false positives. This is in agreement with an FDR of 0.50. If we look at the bar for 0.01, we can see a lower FDR, as expected, but would call less features significant.
h <- hist(pvals,breaks=seq(0,1,0.01))
polygon(c(0,0.01,0.01,0),c(0,0,h$counts[1],h$counts[1]),col="grey")
abline(h=m0/100)
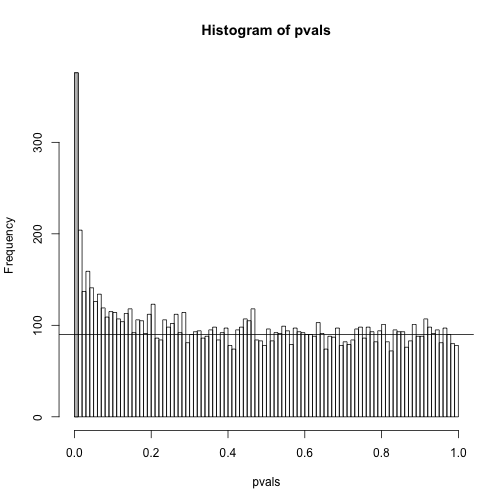
As we consider a lower and lower p-value cut-off, the number of features detected decreases (loss of sensitivity), but our FDR also decreases (gain of specificity). So how do we decide on this cut-off? One approach is to set a desired FDR level , and then develop procedures that control the error rate: FDR .
Benjamini-Hochberg (Advanced)
We want to construct a procedure that guarantees the FDR to be below a certain level . For any given , the Benjamini-Hochberg (1995) procedure is very practical because it simply requires that we are able to compute p-values for each of the individual tests and this permits a procedure to be defined.
For this procedure, order the p-values in increasing order: . Then define to be the largest for which
The procedure is to reject tests with p-values smaller or equal to . Here is an example of how we would select the with code using the p-values computed above:
alpha <- 0.05
i = seq(along=pvals)
mypar(1,2)
plot(i,sort(pvals))
abline(0,i/m*alpha)
##close-up
plot(i[1:15],sort(pvals)[1:15],main="Close-up")
abline(0,i/m*alpha)
![]()
k <- max( which( sort(pvals) < i/m*alpha) )
cutoff <- sort(pvals)[k]
cat("k =",k,"p-value cutoff=",cutoff)
## k = 11 p-value cutoff= 3.763357e-05
We can show mathematically that this procedure has FDR lower than 5%. Please see Benjamini-Hochberg (1995) for details. An important outcome is that we now have selected 11 tests instead of just 2. If we are willing to set an FDR of 50% (this means we expect at least 1/2 our genes to be hits), then this list grows to 1063. The FWER does not provide this flexibility since any list of substantial size will result in an FWER of 1.
Keep in mind that we don’t have to run the complicated code above as we have functions to do this. For example, using the p-values pvals computed above,
we simply type the following:
fdr <- p.adjust(pvals, method="fdr")
mypar(1,1)
plot(pvals,fdr,log="xy")
abline(h=alpha,v=cutoff) ##cutoff was computed above
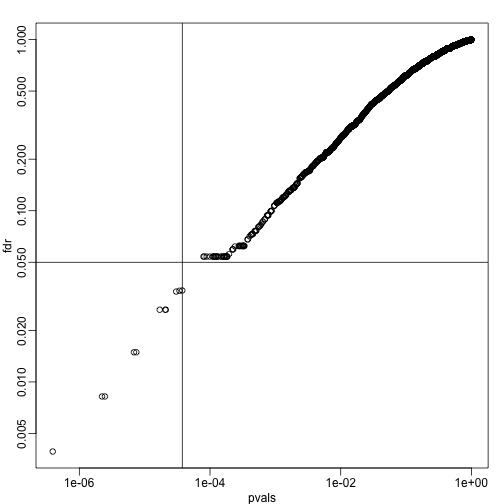
We can run a Monte-Carlo simulation to confirm that the FDR is in fact lower than .05. We compute all p-values first, and then use these to decide which get called.
alpha <- 0.05
B <- 1000 ##number of simulations. We should increase for more precision
res <- replicate(B,{
controls <- matrix(sample(population, N*m, replace=TRUE),nrow=m)
treatments <- matrix(sample(population, N*m, replace=TRUE),nrow=m)
treatments[which(!nullHypothesis),]<-treatments[which(!nullHypothesis),]+delta
dat <- cbind(controls,treatments)
pvals <- rowttests(dat,g)$p.value
##then the FDR
calls <- p.adjust(pvals,method="fdr") < alpha
R=sum(calls)
Q=ifelse(R>0,sum(nullHypothesis & calls)/R,0)
return(c(R,Q))
})
Qs <- res[2,]
mypar(1,1)
hist(Qs) ##Q is a random variable, this is its distribution
FDR=mean(Qs)
print(FDR)
## [1] 0.03813818
The FDR is lower than 0.05. This is to be expected because we need to be conservative to assure the FDR 0.05 for any value of , such as for the extreme case where every hypothesis tested is null: . If you re-do the simulation above for this case, you will find that the FDR increases.
We should also note that in …
Rs <- res[1,]
mean(Rs==0)*100
## [1] 0.7
… percent of the simulations, we did not call any genes significant.
Finally, note that the p.adjust function has several options for error rate controlling procedures:
p.adjust.methods
## [1] "holm" "hochberg" "hommel" "bonferroni" "BH"
## [6] "BY" "fdr" "none"
It is important to remember that these options offer not just different approaches to estimating error rates, but also that different error rates are estimated: namely FWER and FDR. This is an important distinction. More information is available from:
?p.adjust
In summary, requiring that FDR 0.05 is a much more lenient requirement FWER 0.05. Although we will end up with more false positives, FDR gives us much more power. This makes it particularly appropriate for discovery phase experiments where we may accept FDR levels much higher than 0.05.
Direct Approach to FDR and q-values (Advanced)
Here we review the results described by John D. Storey in J. R. Statist. Soc. B (2002). One major distinction between Storey’s approach and Benjamini and Hochberg’s is that we are no longer going to set a level a priori. Because in many high-throughput experiments we are interested in obtaining some list for validation, we can instead decide beforehand that we will consider all tests with p-values smaller than 0.01. We then want to attach an estimate of an error rate. Using this approach, we are guaranteed to have . Note that in the FDR definition above we assigned in the case that . We were therefore computing:
In the approach proposed by Storey, we condition on having a non-empty list, which implies , and we instead compute the positive FDR
A second distinction is that while Benjamini and Hochberg’s procedure controls under the worst case scenario, in which all null hypotheses are true ( ), Storey proposes that we actually try to estimate from the data. Because in high-throughput experiments we have so much data, this is certainly possible. The general idea is to pick a relatively high value p-value cut-off, call it , and assume that tests obtaining p-values > are mostly from cases in which the null hypothesis holds. We can then estimate as:
There are more sophisticated procedures than this, but they follow the same general idea. Here is an example setting . Using the p-values computed above we have:
hist(pvals,breaks=seq(0,1,0.05),freq=FALSE)
lambda = 0.1
pi0=sum(pvals> lambda) /((1-lambda)*m)
abline(h= pi0)
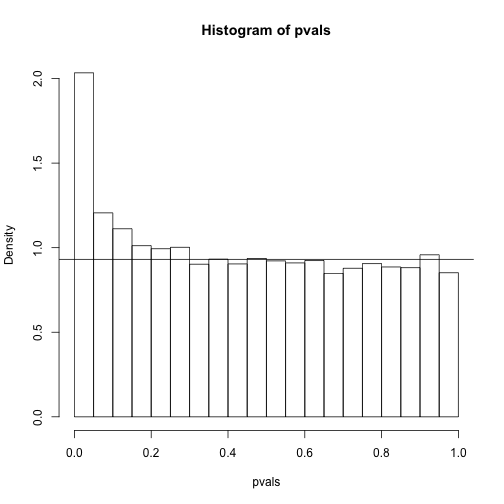
print(pi0) ##this is close to the trye pi0=0.9
## [1] 0.9311111
With this estimate in place we can, for example, alter the Benjamini and Hochberg procedures to select the to be the largest value so that:
However, instead of doing this, we compute a q-value for each test. If a feature resulted in a p-value of , the q-value is the estimated pFDR for a list of all the features with a p-value at least as small as .
In R, this can be computed with the qvalue function in the qvalue package:
library(qvalue)
res <- qvalue(pvals)
qvals <- res$qvalues
plot(pvals,qvals)
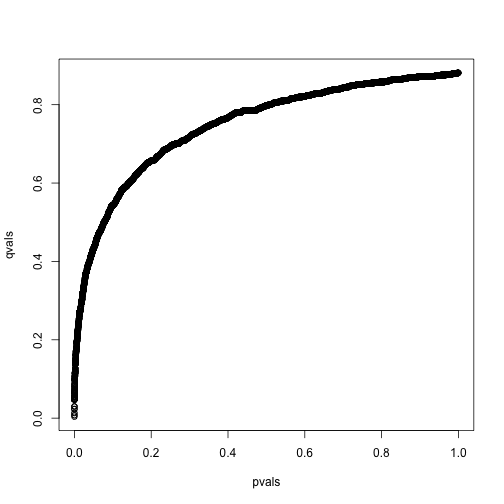
we also obtain the estimate of :
res$pi0
## [1] 0.8813727
This function uses a more sophisticated approach at estimating than what is described above.
Note on estimating
In our experience the estimation of can be unstable and adds a step of uncertainty to the data analysis pipeline. Although more conservative, the Benjamini-Hochberg procedure is computationally more stable.