Power calculations
Power Calculations
Introduction
We have used the example of the effects of two different diets on the weight of mice. Since in this illustrative example we have access to the population, we know that in fact there is a substantial (about 10%) difference between the average weights of the two populations:
library(dplyr)
dat <- read.csv("mice_pheno.csv") #Previously downloaded
controlPopulation <- filter(dat,Sex == "F" & Diet == "chow") %>%
select(Bodyweight) %>% unlist
hfPopulation <- filter(dat,Sex == "F" & Diet == "hf") %>%
select(Bodyweight) %>% unlist
mu_hf <- mean(hfPopulation)
mu_control <- mean(controlPopulation)
print(mu_hf - mu_control)
## [1] 2.375517
print((mu_hf - mu_control)/mu_control * 100) # percent increase
## [1] 9.942157
We have also seen that, in some cases, when we take a sample and perform a t-test, we don’t always get a p-value smaller than 0.05. For example, here is a case were we take sample of 5 mice and don’t achieve statistical significance at the 0.05 level:
set.seed(1)
N <- 5
hf <- sample(hfPopulation,N)
control <- sample(controlPopulation,N)
t.test(hf,control)$p.value
## [1] 0.1410204
Did we make a mistake? By not rejecting the null hypothesis, are we saying the diet has no effect? The answer to this question is no. All we can say is that we did not reject the null hypothesis. But this does not necessarily imply that the null is true. The problem is that, in this particular instance, we don’t have enough power, a term we are now going to define. If you are doing scientific research, it is very likely that you will have to do a power calculation at some point. In many cases, it is an ethical obligation as it can help you avoid sacrificing mice unnecessarily or limiting the number of human subjects exposed to potential risk in a study. Here we explain what statistical power means.
Types Of Error
Whenever we perform a statistical test, we are aware that we may make a mistake. This is why our p-values are not 0. Under the null, there is always a positive, perhaps very small, but still positive chance that we will reject the null when it is true. If the p-value is 0.05, it will happen 1 out of 20 times. This error is called type I error by statisticians.
A type I error is defined as rejecting the null when we should not. This is also referred to as a false positive. So why do we then use 0.05? Shouldn’t we use 0.000001 to be really sure? The reason we don’t use infinitesimal cut-offs to avoid type I errors at all cost is that there is another error we can commit: to not reject the null when we should. This is called a type II error or a false negative. The R code analysis above shows an example of a false negative: we did not reject the null hypothesis (at the 0.05 level) and, because we happen to know and peeked at the true population means, we know there is in fact a difference. Had we used a p-value cutoff of 0.25, we would not have made this mistake. However, in general, are we comfortable with a type I error rate of 1 in 4? Usually we are not.
The 0.05 and 0.01 Cut-offs Are Arbitrary
Most journals and regulatory agencies frequently insist that results be significant at the 0.01 or 0.05 levels. Of course there is nothing special about these numbers other than the fact that some of the first papers on p-values used these values as examples. Part of the goal of this book is to give readers a good understanding of what p-values and confidence intervals are so that these choices can be judged in an informed way. Unfortunately, in science, these cut-offs are applied somewhat mindlessly, but that topic is part of a complicated debate.
Power Calculation
Power is the probability of rejecting the null when the null is
false. Of course “when the null is false” is a complicated statement
because it can be false in many ways.
could be anything and the power actually depends on this parameter. It
also depends on the standard error of your estimates which in turn
depends on the sample size and the population standard deviations. In
practice, we don’t know these so we usually report power for several
plausible values of , , and various
sample sizes.
Statistical theory gives us formulas to calculate
power. The pwr package performs these calculations for you. Here we
will illustrate the concepts behind power by coding up simulations in R.
Suppose our sample size is:
N <- 12
and we will reject the null hypothesis at:
alpha <- 0.05
What is our power with this particular data? We will compute this probability by re-running the exercise many times and calculating the proportion of times the null hypothesis is rejected. Specifically, we will run:
B <- 2000
simulations. The simulation is as follows: we take a sample of size from both control and treatment groups, we perform a t-test comparing these two, and report if the p-value is less than alpha or not. We write a function that does this:
reject <- function(N, alpha=0.05){
hf <- sample(hfPopulation,N)
control <- sample(controlPopulation,N)
pval <- t.test(hf,control)$p.value
pval < alpha
}
Here is an example of one simulation for a sample size of 12. The call to reject answers the question “Did we reject?”
reject(12)
## [1] FALSE
Now we can use the replicate function to do this B times.
rejections <- replicate(B,reject(N))
Our power is just the proportion of times we correctly reject. So with our power is only:
mean(rejections)
## [1] 0.2145
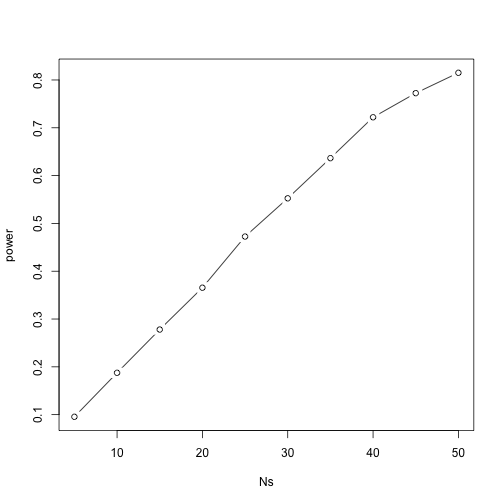
This explains why the t-test was not rejecting when we knew the null was false. With a sample size of just 12, our power is about 23%. To guard against false positives at the 0.05 level, we had set the threshold at a high enough level that resulted in many type II errors.
Let’s see how power improves with N. We will use the function sapply, which applies a function to each of the elements of a vector. We want to repeat the above for the following sample size:
Ns <- seq(5, 50, 5)
So we use apply like this:
power <- sapply(Ns,function(N){
rejections <- replicate(B, reject(N))
mean(rejections)
})
For each of the three simulations, the above code returns the proportion of times we reject. Not surprisingly power increases with N:
plot(Ns, power, type="b")
Similarly, if we change the level alpha at which we reject, power
changes. The smaller I want the chance of type I error to be, the less
power I will have. Another way of saying this is that we trade off
between the two types of error. We can see this by writing similar code, but
keeping fixed and considering several values of alpha:
N <- 30
alphas <- c(0.1,0.05,0.01,0.001,0.0001)
power <- sapply(alphas,function(alpha){
rejections <- replicate(B,reject(N,alpha=alpha))
mean(rejections)
})
plot(alphas, power, xlab="alpha", type="b", log="x")
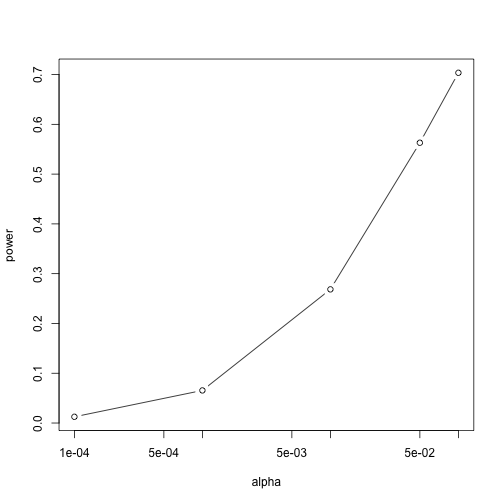
Note that the x-axis in this last plot is in the log scale.
There is no “right” power or “right” alpha level, but it is important that you understand what each means.
To see this clearly, you could create a plot with curves of power versus N. Show several curves in the same plot with color representing alpha level.
p-values are Arbitrary under the Alternative Hypothesis
Another consequence of what we have learned about power is that p-values are somewhat arbitrary when the null hypothesis is not true and therefore the alternative hypothesis is true (the difference between the population means is not zero). When the alternative hypothesis is true, we can make a p-value as small as we want simply by increasing the sample size (supposing that we have an infinite population to sample from). We can show this property of p-values by drawing larger and larger samples from our population and calculating p-values. This works because, in our case, we know that the alternative hypothesis is true, since we have access to the populations and can calculate the difference in their means.
First write a function that returns a p-value for a given sample size :
calculatePvalue <- function(N) {
hf <- sample(hfPopulation,N)
control <- sample(controlPopulation,N)
t.test(hf,control)$p.value
}
We have a limit here of 200 for the high-fat diet population, but we can see the effect well before we get to 200. For each sample size, we will calculate a few p-values. We can do this by repeating each value of a few times.
Ns <- seq(10,200,by=10)
Ns_rep <- rep(Ns, each=10)
Again we use sapply to run our simulations:
pvalues <- sapply(Ns_rep, calculatePvalue)
Now we can plot the 10 p-values we generated for each sample size:
plot(Ns_rep, pvalues, log="y", xlab="sample size",
ylab="p-values")
abline(h=c(.01, .05), col="red", lwd=2)
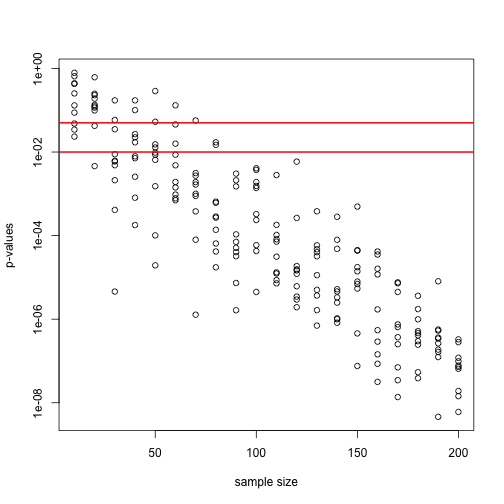
Note that the y-axis is log scale and that the p-values show a decreasing trend all the way to as the sample size gets larger. The standard cutoffs of 0.01 and 0.05 are indicated with horizontal red lines.
It is important to remember that p-values are not more interesting as they become very very small. Once we have convinced ourselves to reject the null hypothesis at a threshold we find reasonable, having an even smaller p-value just means that we sampled more mice than was necessary. Having a larger sample size does help to increase the precision of our estimate of the difference , but the fact that the p-value becomes very very small is just a natural consequence of the mathematics of the test. The p-values get smaller and smaller with increasing sample size because the numerator of the t-statistic has (for equal sized groups, and a similar effect occurs when ). Therefore, if is non-zero, the t-statistic will increase with .
Therefore, a better statistic to report is the effect size with a confidence interval or some statistic which gives the reader a sense of the change in a meaningful scale. We can report the effect size as a percent by dividing the difference and the confidence interval by the control population mean:
N <- 12
hf <- sample(hfPopulation, N)
control <- sample(controlPopulation, N)
diff <- mean(hf) - mean(control)
diff / mean(control) * 100
## [1] 1.868663
t.test(hf, control)$conf.int / mean(control) * 100
## [1] -20.94576 24.68309
## attr(,"conf.level")
## [1] 0.95
In addition, we can report a statistic called Cohen’s d, which is the difference between the groups divided by the pooled standard deviation of the two groups.
sd_pool <- sqrt(((N-1)*var(hf) + (N-1)*var(control))/(2*N - 2))
diff / sd_pool
## [1] 0.07140083
This tells us how many standard deviations of the data the mean of the high-fat diet group is from the control group. Under the alternative hypothesis, unlike the t-statistic which is guaranteed to increase, the effect size and Cohen’s d will become more precise.